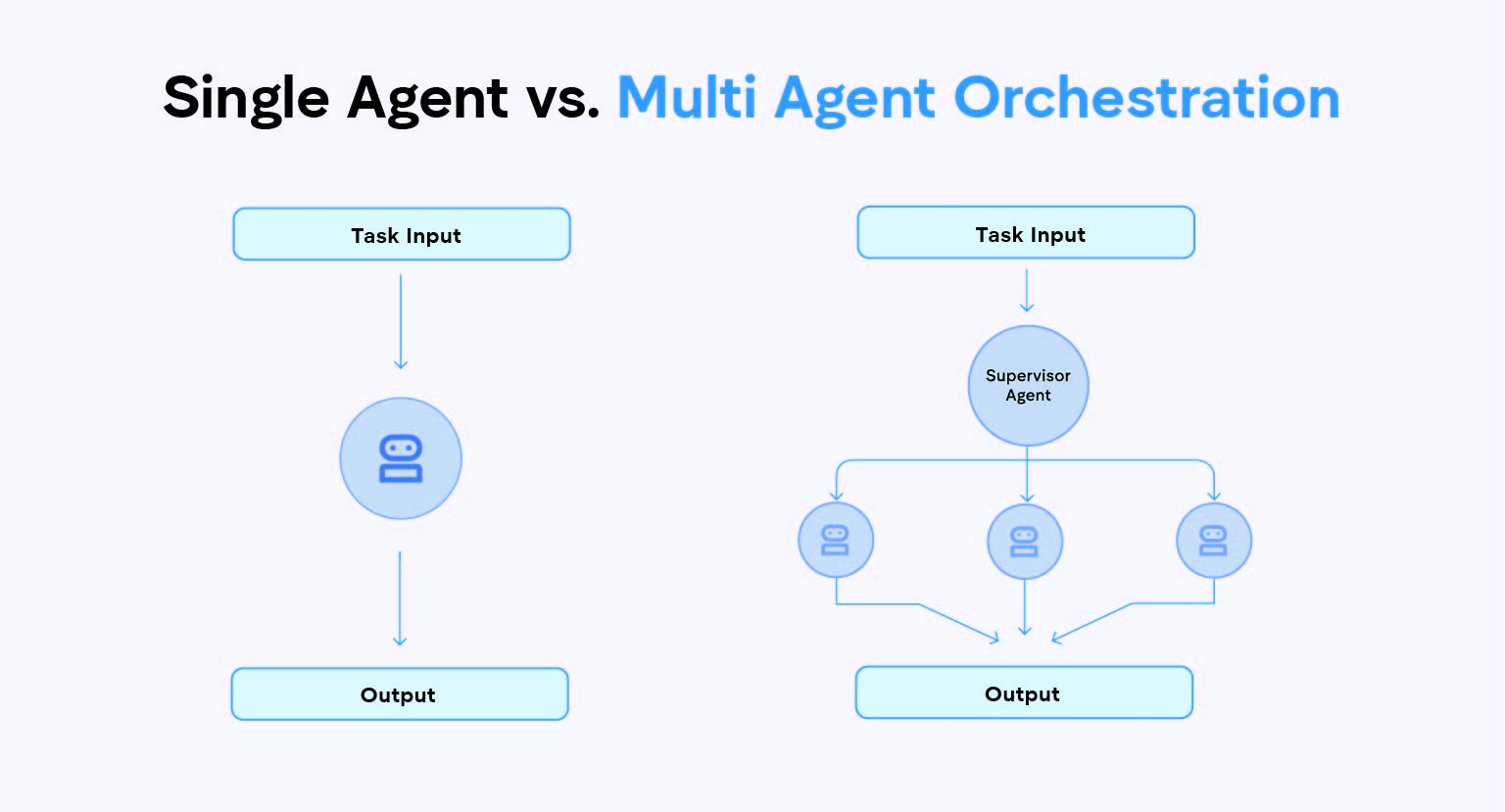
We stand at a critical inflection point in the Agentic Era of 2026. For years, the prevailing belief was that the pinnacle of AI implementation was a state of complete Human-out-of-the-loop autonomy. The goal was total autonomy. The reality, as many leaders are now finding, is much more volatile.
The irresistible promise of enterprise AI, specifically for enterprise operations, has always been set it and forget it. But as many leaders are now realizing, in high-stakes environments, that’s not just an efficiency play; it's a profound systemic risk.
The real threat to the modern enterprise isn't the difficulty of deploying AI, but Blind Automation.
When AI agents and squads operate without a clearly defined enterprise AI governance framework, a single hallucination, an overlooked clause in a contract analysis, or a slightly miscalibrated parameter in a supply chain forecast no longer just creates a bad output; it triggers an automated, systemic failure that ripples through your organization instantly.
This isn't just a theoretical concern; research from late 2025 indicates that unstructured AI agent networks can amplify errors by up to 17.2 times compared to single-agent baselines when left without a structured governance topology. (Towards Data science)
Operational excellence in 2026 isn't found in replacing humans. It’s about architecting precise Human-in-the-Loop (HITL) systems that move your professionals from operators (doing the work) to architects (verifying the blueprints).
This article provides the roadmap for that architecture.
The Trust Gap: Why Chatbots Fail The Enterprise Test
The enterprise trust gap is the distance between what AI can do and what it should be allowed to do unescorted.
In the low-stakes world of customer service or content ideation, an AI that is 90% accurate is a miracle. In the high-stakes world of analyzing a massive corporate RFP or interpreting a radiology scan, 90% accuracy is a catastrophe.
For most businesses, unverified AI is not useful as a productivity enhancer if every single output must be meticulously fact-checked by a senior analyst. HITL is not a fallback for a weak AI; it is the fundamental bridge that takes a process from a risky "90%" to the "100% reliability" mandatory for regulated industries.
As the 2026 Securitas Risk Intelligence Estimate notes “High confidence does not equal high relevance. The future of enterprise AI is not about who has the most autonomous algorithms, but who has the most accountable workflows.”
To understand why traditional tools fall short in these scenarios, see our breakdown: Chatbots vs. AI Agents: What’s the Real Difference?
The Three Pillars of Human-in-the-Loop Governance
%20(1).png)
The biggest misconception about HITL is that it reintroduces manual labor. It doesn't. When properly architected, HITL introduces strategic validation. We define this through three key governance frameworks that must be mapped to specific business processes:
- Human-in (Blocking): The human is a strict requirement. Every output (such as a complex legal opinion) must be verified and approved by a human agent before it is finalized or sent. (Best for: Legal opinions, $100k+ payments).
- Human-on (Monitoring): The human monitors the process from a commander’s dashboard. The AI makes decisions automatically, but a human can intervene instantly if they flag an anomaly, or if the system self-reports a safety trigger. (Best for: High-volume logistics, customer routing).
- Human-out-of-the-loop (Autonomous): The human is removed entirely. This is generally reserved only for extremely low-stakes or read-only data tasks with no potential for legal or safety impact.
Engineering The Approval Gate
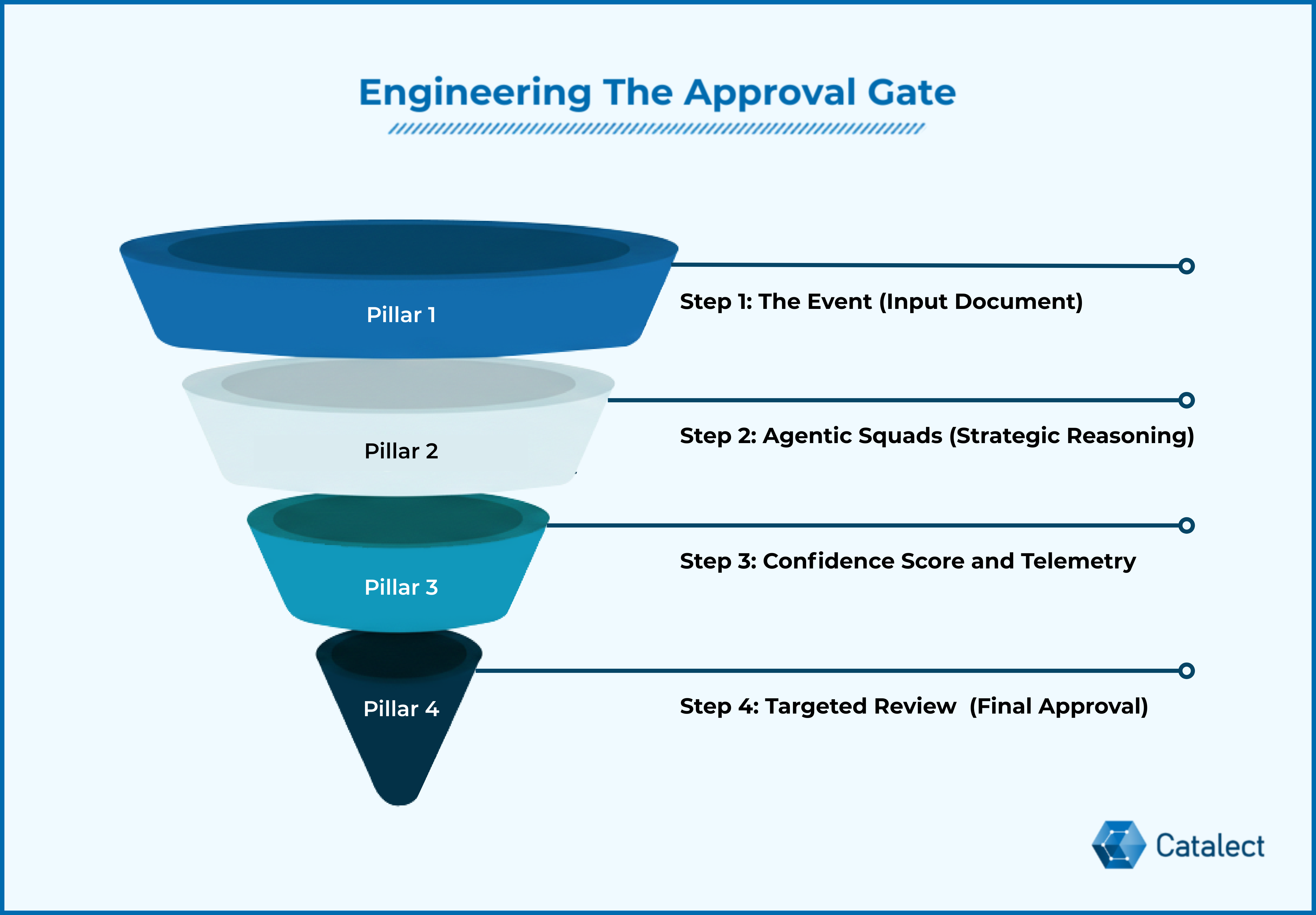
So, how do you operationalize this level of control without losing the speed of AI? You build an Approval Gate. This is the system architecture that turns governance into code. At Catalect, we follow a four-step workflow:
Step 1: The Event
A high-priority document (like a multi-vendor MSA) enters the ecosystem.
Step 2: Processing by Agentic Squads
Specialized AI agents handle specific pieces, financial risk, legal compliance, and technical specs. The squads don't just extract text; they perform strategic reasoning. They compare clauses against your internal guidelines and past precedents stored in your knowledge base.
Before deploying these squads, ensure your foundation is solid with our: Enterprise Guide to Data Preparation.
Step 3: The Confidence Score
Here is the core technical difference. The Agentic Squad doesn't just present the final contract; it presents a Confidence Score and Decision Telemetry. The system assigns a Confidence Score (0.0 to 1.0) to every decision.
- High Confidence (>0.95): The system proceeds to a draft ready state.
- Low Confidence (<0.85): The task is frozen and escalated.
Step 4: Targeted Review
The human professional doesn't have to re-read the whole document. They are routed directly to the exception. They review the telemetry, make a judgment, and finalize the output with a single click.
Consider a Global Insurance firm. Previously, a senior adjuster could handle 15 complex claims a day. By implementing the Approval Gate, the AI squads handle the document extraction and policy cross-referencing for 150 claims. The adjuster is only alerted to the 8 claims where Confidence Scores were low due to ambiguous liability language. The result? 10x capacity with 0% increase in risk. (druidai.com)
Reducing Cognitive Load Without Losing Control
The argument against HITL is often that it slows things down. We disagree. The goal of a proper HITL blueprint is not more work, it is right work.
This approach fundamentally shifts the role of your elite professionals. You are not hiring them to operate the machine anymore; you are hiring them to operate the blueprints.
By solving for cognitive cost of AI, specifically decision fatigue in modern monitoring systems, you allow a single manager to rely on the system to handle 95% of standard tasks, while they focus exclusively on the 5% that are standard, that single manager can effectively oversee 10x the previous volume.
This shift is the answer to the trust paralysis currently sweeping the C-Suite; Deloitte’s 2026 'State of AI' report found that 72% of leaders have stalled AI projects because they lack a unified, trusted governance strategy. (Deloitte)
Safety, Ethics, And Governance As A Capability
Finally, HITL is your most effective tool for long-term safety. In industries where audit trails must be absolute (like GxP or legal services), HITL provides an explicit signature. This audit trail is your primary defense against:
- AI Bias Mitigation: AI trained on stale or imperfect data will propagate bias. Human review is the necessary filter to prevent these errors from scaling.
- Regulatory Compliance: New frameworks (like the EU AI Act) are beginning to require high-impact AI systems to have explicit human oversight capabilities. HITL is no longer optional; it is becoming the new standard for legal operation.
The Hidden Risk of Status Quo
As we move deeper into 2026, the question is no longer, "Can we automate this?" It must be: "Do we trust this automation with our reputation?"
If you want to scale AI, you must build trust directly into the workflow code. At Catalect, we don’t just build AI agents; we build the foundational governance layers that make AI safe for the world’s most critical industries.
We don’t believe in blind automation. We believe in augmented certainty.
Ready to bridge your trust gap? Contact us for a governance audit.