.jpg)
Machine learning promises to transform the way enterprises operate, from forecasting demand in retail to predicting patient outcomes in healthcare. Yet behind the success stories, there’s a hard truth: most machine learning projects fail before they even start.
The culprit isn’t the sophistication of algorithms. It’s the quality of the data. A model is only as good as the data it’s built on, and when that foundation is weak, everything built on top collapses. In fact, a Forbes study revealed that 80% of a data scientist’s time is spent cleaning and preparing data, not running algorithms (Forbes). For enterprises, this step often makes or breaks the success of AI initiatives.
In this guide, we’ll explore why data preparation is critical for machine learning, the challenges enterprises face, and the best practices that turn raw information into reliable insights.
What is Data Preparation for Machine Learning?
At its core, data preparation means transforming messy, scattered, real-world business data into a structured, reliable foundation for models. This process directly impacts:
- Model Accuracy – Poor-quality data produces unreliable predictions.
- Time to Value – Clean, structured data speeds up experimentation and deployment.
- Enterprise Scale – Well-prepared data enables ML adoption across departments and use cases.
Consider healthcare: if clinical records contain duplicates or missing values, even the most advanced algorithm could generate misleading outcomes. In retail, inaccurate demand data can trigger costly overstock or stockouts. In finance, compliance risks arise if unstructured transaction data isn’t standardized.
Why Data Preparation Matters
Without proper preparation:
- Garbage in, garbage out → Inaccurate or misleading predictions.
- Bias and imbalance → Models amplify errors if the data is skewed.
- Compliance risks → Mishandled sensitive data may lead to lawsuits or fines.
From a business perspective, this translates into wasted resources, failed AI projects, and missed opportunities. Gartner estimates that poor data quality costs organizations an average of $12.9M annually (Data Quality: Why It Matters and How to Achieve It).
Simply put: the importance of data preparation in machine learning projects cannot be overstated.
Steps in Data Preparation
Many assume “preparing data” means removing a few errors or null values. In reality, data preparation for ML is a structured, multi-step process that includes:
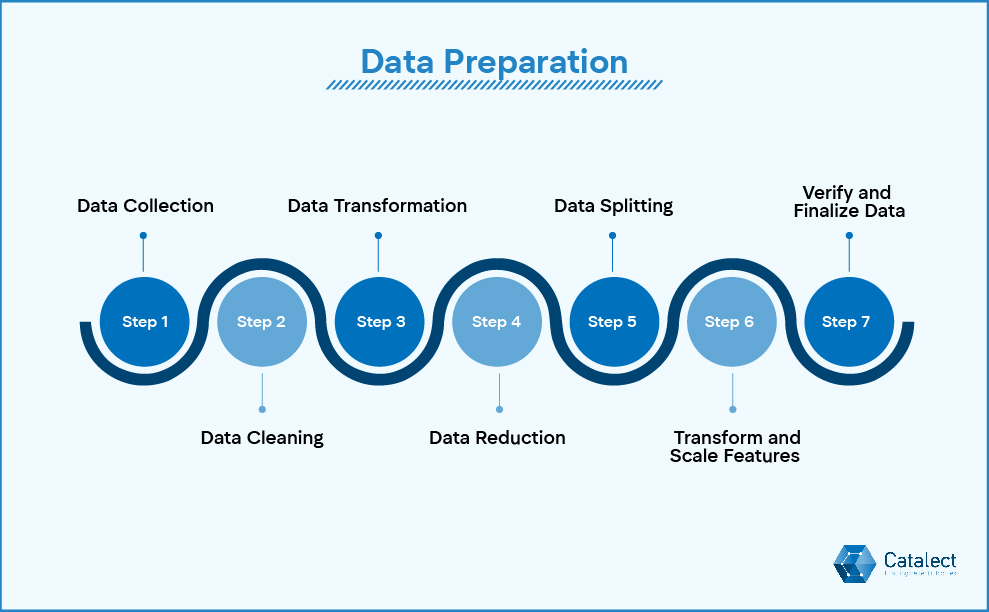
1. Data Collection
The first step is to bring together raw data from all relevant sources such as CRM systems, ERP software, IoT devices, APIs, or open repositories. Each source may store information in very different ways, with some being structured like SQL tables and others being unstructured such as text, images, or videos. While structured data is usually easy to export, unstructured data often requires more effort, including scraping or building streaming pipelines. Having a clear strategy for what to collect, how to validate it, and how to integrate it helps avoid problems later and provides a strong base for modeling.
Step 2: Data Cleaning
Raw data usually comes with problems such as errors, missing entries, duplicates, or inconsistent formatting, so the next step is to fix these issues. Missing values can sometimes be estimated with statistical techniques, but in some cases entire records may need to be removed if they cannot be trusted. Inconsistent formats, like country names written differently across systems, must be standardized so the dataset is uniform. Outliers that sit far outside normal patterns also need to be checked, since they can skew results if left uncorrected. Proper cleaning makes the dataset more reliable and greatly improves the accuracy of the model.
Step 3: Data Transformation
Cleaned data still needs to be reshaped into a form that algorithms can use effectively. This can involve encoding categories into numbers, breaking text into tokens, or scaling values into a consistent range. For example, a sentiment analysis system cannot process words directly, so words are converted into numerical tokens before analysis. In another case, a logistics company might have distances listed in both miles and kilometers and would need to standardize them into a single measurement. Transformation ensures that the data aligns with the technical requirements of the algorithms being used.
Step 4: Data Reduction
Large datasets often include more features than are truly useful, which can slow down analysis and make models more complicated than necessary. Data reduction focuses on removing variables that are redundant while keeping the information that matters most. This might involve dropping one of two features that essentially capture the same idea, like keeping a ZIP code while removing a city field. In other cases, statistical techniques such as principal component analysis (PCA) can help condense many features into a smaller set. The result is a dataset that is easier to process, trains faster, and is less likely to produce models that overfit.
Step 5: Data Splitting
To check that a model is learning properly, the dataset must be divided into training, validation, and test sets. The training set is used to build the model, the validation set is used to tune its parameters, and the test set provides a fair measure of how it performs on new information. Ratios such as 70/20/10 or 80/20 are common, but the right split depends on the size and complexity of the dataset. A careful split also prevents data leakage, where information from the test set accidentally influences training. This step ensures the model performs well on data it has never seen before.
Step 6: Transform and Scale Features
Even after earlier transformations, many features need to be scaled so that no single variable dominates the model. Normalization adjusts values to fall within a fixed range, often between 0 and 1, while standardization centers them around zero with a standard deviation of one. Categorical variables may also need to be turned into numerical form through one-hot encoding or embeddings. For example, a bank preparing a fraud detection model may normalize transaction amounts, so that unusually large values do not overwhelm the rest of the data. This makes algorithms, especially those sensitive to scale like SVMs or KNN, work more effectively.
Step 7: Verify and Finalize Data
The last step is to check that the dataset is truly ready for modeling. Analysts look at distributions to spot unusual values, confirm that no data leakage has taken place, and make sure that preprocessing has been applied consistently. This stage also involves documenting how issues such as missing values, outliers, and categorical encodings were handled. Once the checks are complete, the dataset is exported into a stable and version-controlled format so that the process can be reproduced later. A well-finalized dataset gives confidence that the ML pipeline can be run smoothly and reliably.
Challenges in Data Preparation
Of course, knowing the steps doesn’t mean they’re easy to execute. Enterprises often run into significant hurdles, such as:
- Data Silos: Marketing, finance, and operations store fragmented data differently.
- Unstructured Data: Emails, PDFs, and audio require advanced preprocessing (NLP, OCR).
- Imbalanced Datasets: Fraud detection often has one fraud per 10,000 records, making models biased.
- Resource Constraints: Manual cleaning consumes time and budgets.
- Tool Overload Teams: Teams often juggle Excel, custom Python scripts, and multiple data platforms at once, which causes inefficiency.
5. Best Practices for Effective Data Preparation
Tackling these challenges requires a disciplined, business-focused approach:
- Define Business Objectives First: Only prepare the data that directly supports the ML goal. Clarity at this stage prevents wasted effort downstream.
- Standardize Data Collection: Create an enterprise-wide data dictionary so “Customer_ID” means the same across every system and department.
- Automate Where Possible: Use platforms like Databricks, Snowflake, or cloud-native MLOps tools to automate repetitive cleaning, transformation, and monitoring tasks. These platforms handle scale efficiently and integrate smoothly into ML pipelines.
- Implement Data Versioning & Lineage: Robust data versioning ensures every dataset can be traced back to its source, while data lineage provides visibility into how data has evolved over time, who modified it, and why. This transparency not only strengthens governance and compliance but also builds trust in the models trained on that data.
- Document Every Step: Maintain compliance-ready documentation that captures processes, assumptions, and transformations. This guarantees reproducibility and auditability.
- Validate Continuously: Run anomaly detection scripts early and often to catch quality issues before they affect model performance.
- Prioritize Interpretability: Reduce features thoughtfully, ensuring that model outputs remain explainable and actionable for business users.
- Plan for Scalability: Build with cloud-native storage solutions (e.g., AWS S3, Azure Data Lake) to ensure data pipelines grow alongside enterprise needs.
Moving From Theory to Practice
Best practices provide a roadmap, but execution is where enterprises often struggle. Scaling across departments, embedding compliance safeguards, and aligning preparation with business goals can quickly overwhelm teams without the right systems in place.
The good news is that these challenges are solvable. With the right mix of automation, governance, and strategy, enterprises can transform data preparation from a bottleneck into a competitive advantage.
Now is the moment to act: organizations that invest in structured, scalable data preparation today position themselves to unlock faster AI adoption, reduce costs, and gain a clear competitive edge tomorrow.